
티스토리 뷰
오늘의 주제는 라우팅 알고리즘입니다.
본격적으로 라우팅 알고리즘에 대해 작성하기 전에, 그럼 라우팅이 뭔지부터 알고 넘어가야겠죠?
라우팅: 어떤 네트워크 안에서 통신 데이터를 보낼 때 최적의 경로를 선택하는 과정
= 패킷이 목적지에 도달할 최적의 경로를 찾아 전송하는 것
입니다~
네트워크층에서 최적의 경로를 찾는 방법~ 이라고 생각하시면 좋을 것 같아요
예를 들면 각자의 집에서 역삼 멀티캠퍼스까지 가는 가장 최적의 방법을 찾는 것이라고 생각할 수 있습니다.
라우터가 패킷을 목적지까지 전달할 수 있도록 하려면 라우터는 해당 목적지에 대한 경로 정보를 알고 있어야 하며, 이 정보에 따라 패킷을 전달합니다.
따라서 라우터들은 목적지에 대한 경로 정보를 가지고 이웃의 라우터들과 경로 정보를 교환하는데, 이때 경로 정보(라우팅 정보)를 교환하는 Protocol을 라우팅 프로토콜이라고 합니다.
또, 라우트와 라우팅의 차이를 정리하자면 아래와 같은데요,
라우트는 경로 즉 라우팅 프로토콜에 의한 결과이며, 라우팅은 경로를 찾아가게 하는 과정입니다.
근데 그럼 어떻게, 뭘 보고 최적의 경로를 찾을까요?
네 바로 라우팅 테이블이라는 친구를 보고 패킷이 목적지에 어떻게 가장 효율적으로 도착할까를 찾습니다.
그럼 라우팅 테이블이란 뭘까요?
라우팅 테이블: 패킷을 전송할 때 패킷이 목적지 쪽으로 보낼 수 있도록 라우터에게 목적지에 대한 정보를 알려줌
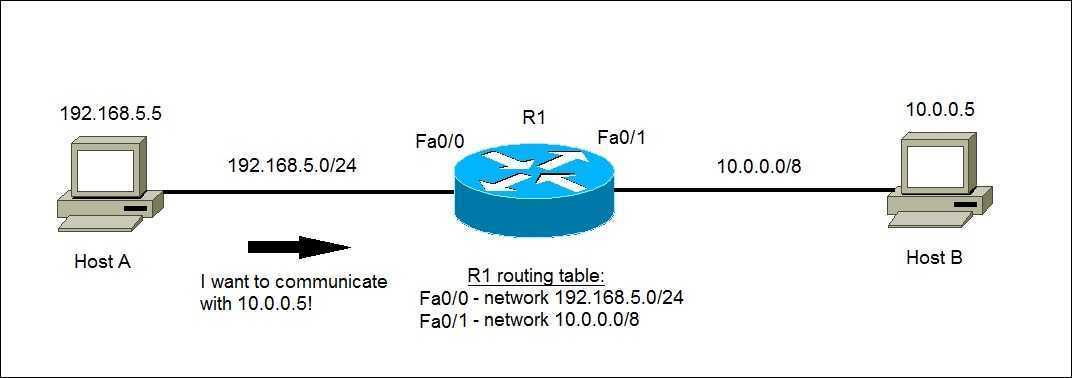
입니다:)
다음으로는 라우팅의 종류에 대해서 알아보겠습니다.
Routing에는 Network Admin이 Router마다 최적의 경로를 인위적으로 등록하는 정적 경로(Static Routing)와 자동적인 Routing Algorithm에 의해 최적의 경로를 판단하는 동적 경로(Dynamic Routing)가 있습니다.

먼저 정적 라우팅에 대해 설명하겠습니다.
정적 라우팅
: 목적지 주소까지 어떻게 가야하는지 사람이 직접 지정하는 방식
= 사람이 직접 경로를 설정해주고 라우터는 입력받은 경로로만 패킷을 전송시킵니다.
- 멀리 떨어져 있는 네트워크를 지정할 때 사용합니다
- 관리자가 명령어로 하나하나 직접 지정합니다.
- 고정적입니다 -> 망 상태의 변화가 일어나도 바뀌지 않아요
- 경로 관리에 효율적이다. (동적 라우팅에 비해 트래픽이 없기때문에)
지정방법
- ip route [목적지 주소] [서브넷 마스크] [address or interface]
- = 목적지 주소까지 가기 위해서는 해당 address가 있는 혹은 해당 interface가 있는 쪽으로 가라는 뜻
ip route [목적지 주소] [서브넷 마스크] [address or interface]을 자세히 보자면,
먼저 목적지 주소는 특정 네트워크의 주소입니다.
address는 나와 연결된 상대방의 IP주소로 ->만약 내 ip 172.16.1.1가 상대방 172.16.1.2와 연결되어있다면 172.16.1.2를 지정합니다.
interface는 자신의 interface를 지정해주면 됩니다.
정적경로 지정 예시
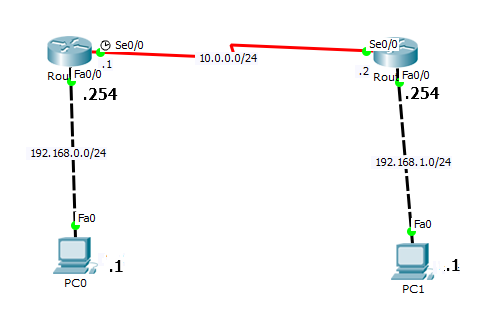
네트워크 토폴로지는 위와같이 되어있고

R1 인터페이스는 위와 같이 할당하고

R2 인터페이스는 위와 같습니다. 이더넷 주소의 차이에 집중해서 봐주세요~
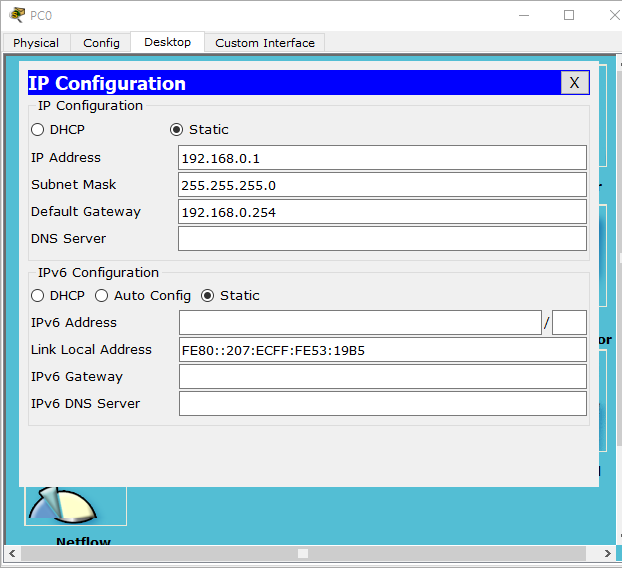
pc 1 설정
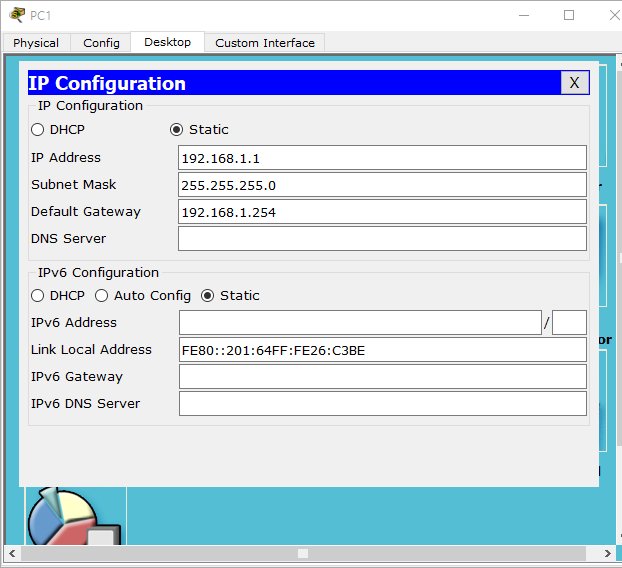
pc 2 설정
위의 그림에서 pc1의 전송 패킷은 pc2로 갈 수 없습니다.
pc1이 pc2를 목적지 주소로하여 패킷을 보낸다면, 해당 패킷은 당연히 게이트웨이인 R1(192.168.0.254)에게 갑니다.
R1은 해당 패킷의 목적지 주소가 pc2의 ip주소인 192.168.1.1 인 것을 알구요.
그러나 문제가 발생합니다.
R1의 Fa 0/0의 대역은 192.168.0.254/24
R1의 Se 0/0의 대역은 10.0.0.1/24
이 때문이죠.
즉 192.168.0.0/24 대역과 10.0.0.0/24 대역 밖에 모르는데, 목적지 주소로 192.168.1.1를 받는다면?
라우터는 어디로 라우팅(보내는 것)해야할 지 알 수 없습니다. -> 고로 해당 패킷을 폐기합니다.
이렇기에 특정 목적지로 가려면 어디로 가라 하는 방향을 직접 지정해 줄 수 있습니다.
R1(config)#ip route 192.168.1.0 255.255.255.0 10.0.0.2
R1에 이런 식으로 지정해주면 방향을 알 수 있습니다.
해당 명령어의 내용은 192.168.1.0 네트워크 대역으로 가고 싶으면 상대방 ip가 10.0.0.2인 쪽으로 가세요.
그러나 해당 명령어만 해주면 R2에서 R1으로 반송 될 때 R2 역시 192.168.0.0/24(pc1 대역)을 알 수 없으므로,
R2(config)#ip route 192.168.0.0 255.255.255.0 S0/0
그러므로 R2에서 위와같이 지정해 줍니다.
위의 두개에서 알 수 있는 것은 방향 지정 시 내 인터페이스와 연결된 상대방 IP 주소(10.0.0.2), 내 인터페이스(s0/0) 둘다 가능하다는 것이에요!
이때 라우팅 테이블을 보면
라우팅 테이블
show ip route 명령어를 이용하자. R1과 R2에서 명령어를 입력하면
R1#show ip route
10.0.0.0/24 is subnetted, 1 subnets
C 10.0.0.0 is directly connected, Serial0/0
C 192.168.0.0/24 is directly connected, FastEthernet0/0
S 192.168.1.0/24 [1/0] via 10.0.0.2
R2#show ip route
10.0.0.0/24 is subnetted, 1 subnets
C 10.0.0.0 is directly connected, Serial0/0
S 192.168.0.0/24 [1/0] via 10.0.0.1
C 192.168.1.0/24 is directly connected, FastEthernet0/0
# stub network
다른 네트워크로 가는데에 오직 하나의 경로만 존재하는 것
해당 경로를 통해야지 다른 네트워크로 갈 수 있으며,
-> 이때는 static routing의 종류 default routing을 사용합니다.
그럼 디폴트 라우팅이란 뭘까요?
목적지 주소가 무엇이든 특정 인터페이스를 지나가게 설정하는 것 입니다.
살짝 답정너 느낌으로 이해하시면 좋을 것 같아여(너의 주소가 뭐든지 다음에 갈 수 있는 주소는 하나야~)
stub network 예시)
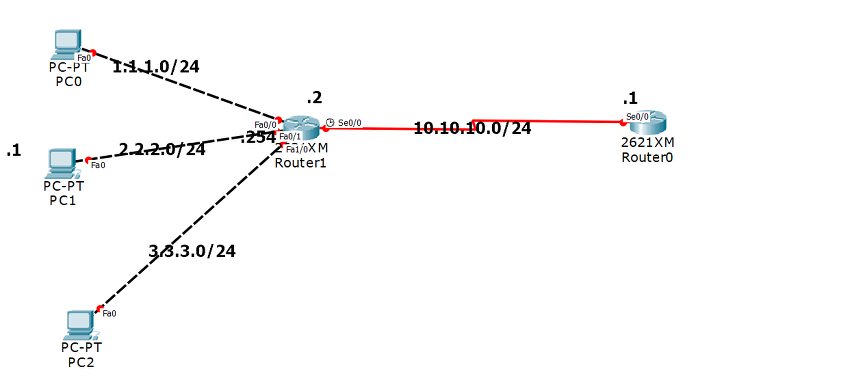
R1(Router0)에서 다른 네트워크로 가기위해서는 무조건 10.10.10.0 네트워크 대역을 지나야하고 이러한 것을 stub network라 합니다.

R1(Router 0)의 인터페이스 정보

R2(Router 1)의 인터페이스
stub network에서 경로를
ip route 1.1.1.0 255.255.255.0 10.10.10.2
ip route 2.2.2.0 255.255.255.0 10.10.10.2
ip route 3.3.3.0 255.255.255.0 10.10.10.2
로 하나하나 지정해주기 번거롭다는 점이 존재합니다.
그래서 이렇게 하지말고
디폴트 라우팅 설정 명령어를
R1(config)#ip route 0.0.0.0 255.255.255.0 10.10.10.2
이렇게 설정하면 좋습니다.
: 모든 네트워크 대역(0.0.0.0/0), 즉 어떤 네트워크 대역이든 10.10.10.2 인터페이스를 지나가야한다는 뜻
그럼 다음으로 동적 라우팅에 대해 설명드리겠습니다.
동적 라우팅 = 자동으로 경로가 결정되는 프로토콜
- 라우터가 알아서 자동으로 라우팅 테이블을 입력
- 사용자는 프로토콜 설정만 해주면 됩니다. (아래에 설명할 라우팅 프로토콜 RIP/OSPF 등의 프로토콜을 선택하면 된다는 소리입니당)
- 네트워크 망 변화 시 Router가 알아서 업데이트
- 라우터 사이에 교환을 위한 트래픽이 발생
그럼 동적 라우팅에 사용되는 라우팅 프로토콜을 같이 한번 봐볼게요~
라우팅 프로토콜의 종류
우선 AS에 따라 두가지로 나뉘는데요,
*AS: 하나의 토폴로지 덩어리, 쉽게 말해 하나로 소속된 라우터들의 장비(SKT 장비, KT 장비)

IGP- AS 내부에서 사용하는 라우팅 프로토콜
EGP- AS 외부에서 사용하는 라우팅 프로토콜
입니다.
IGP 프로토콜은 또 3가지로 나뉘는데요, 가장 많이 쓰이는 라우팅 알고리즘 2가지와 거리벡터 알고리즘의 RIP 프로토콜, 링크상태 알고리즘의 OSPF 프로토콜에 대해 설명드리겠습니다.
이미지 부터 보시져 !
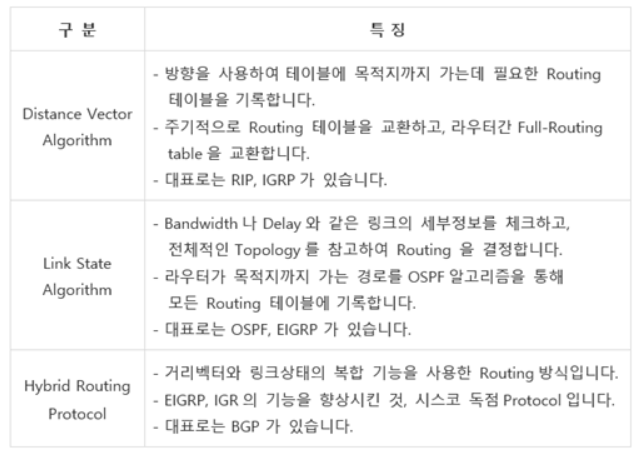
라우팅 알고리즘을 설명하기 전에, 이 알고리즘들은 모두 하나의 근원지에서 하나의 목적지로 패킷을 전달하는 '유니캐스트 라우팅'이라는 것을 알아두세요 !
이 유니캐스트 라우팅은 계층적 라우팅 방식을 사용하는데, 계층적 라우팅 방식은 최소 비용 라우팅 방식으로 구현이 됩니다.
그래서 먼저 이 최소 비용 라우팅을 하는 방법을 설명해드리겠습니다.
(유니캐스트에 대해 자세히 공부하고 싶다면 B팀의 저번주 포스팅을 참고하시면 됩니당)
최소 비용 라우팅을 하기 위해서는 최소 비용 트리를 그리면 되는데, 이를 위해 라우터들의 관계를 그래프로 표현합니다.
그래프 표현
인터넷에서 최적 경로를 찾기 위해 그래프를 이용해 모델링했습니다. 라우터는 노드로, 라우터 사이의 네트워크를 선으로 표현합니다. 각 선 사이에 비용을 연관지어 가중치 그래프를 이용해 모델링할 수 있습니다.
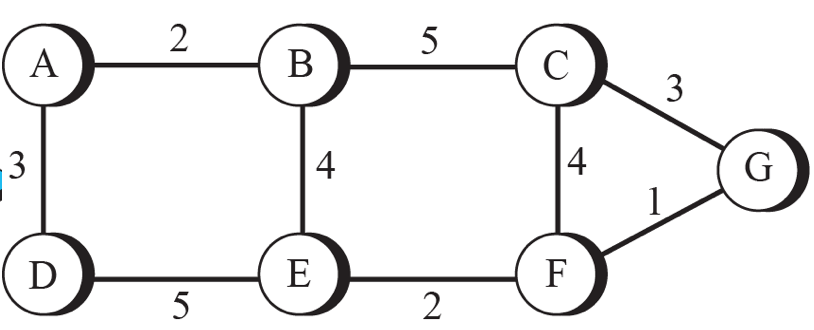
최소 비용 라우팅
가중치 그래프로 인터넷을 모델링할 때, 근원지 라우터부터 목적지 라우터까지의 최적 경로를 표현하는 방법 중 하나입니다.
두 라우터 사이의 최소 비용(least cost)를 찾는 것이쥬
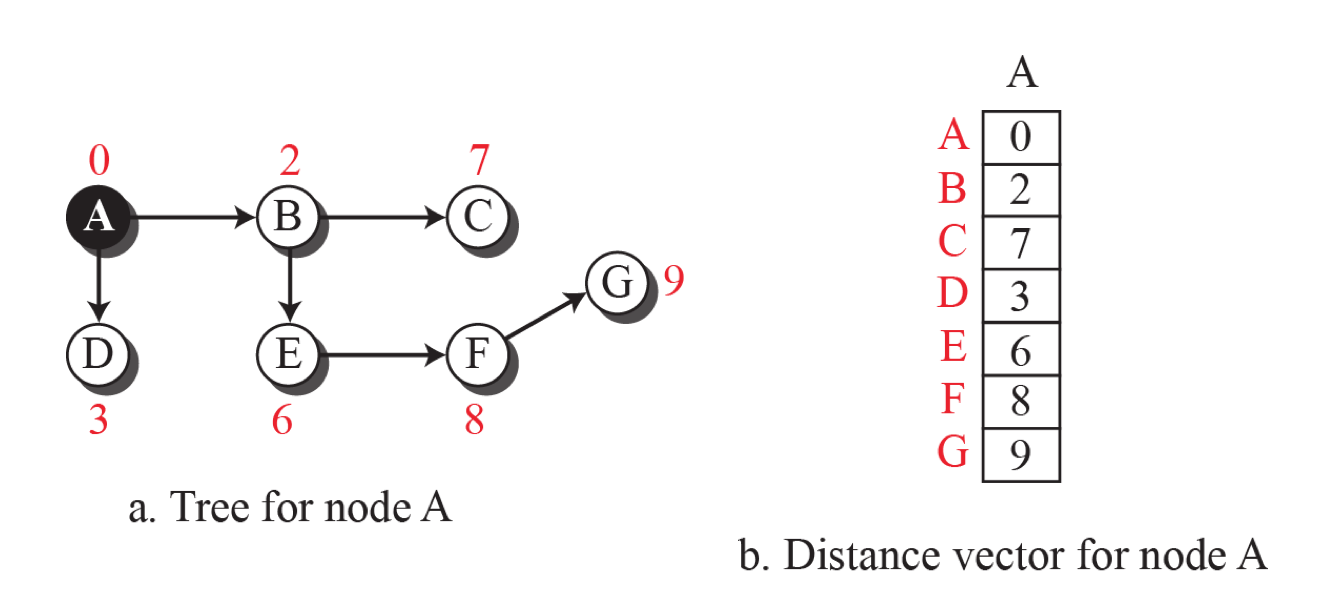
위의 그림에서 A와 E의 최선의 경로는 A-B-E라는 것을 알 수 있죠? 이렇게 각 라우터는 최소 비용 경로를 찾아 라우팅해야합니다.
최소 비용 트리
루트로부터 다른 모든 노드들을 최소 비용으로 방문하는 트리
N개의 라우터가 있다면 각 라우터는 자신만의 최소비용 트리를 가집니다.
루트와 다른 노드 사이의 가장 짧은 경로를 구하기 위해 모든 다른 노드들을 방문하는 트리입니다.
아래 그림은 위에 가중치 그래프에서 갖는 7개의 최소 비용 트리를 보여줍니다.
(각 파란색 노드에서 다른 하얀색 노드로 가는 비용)
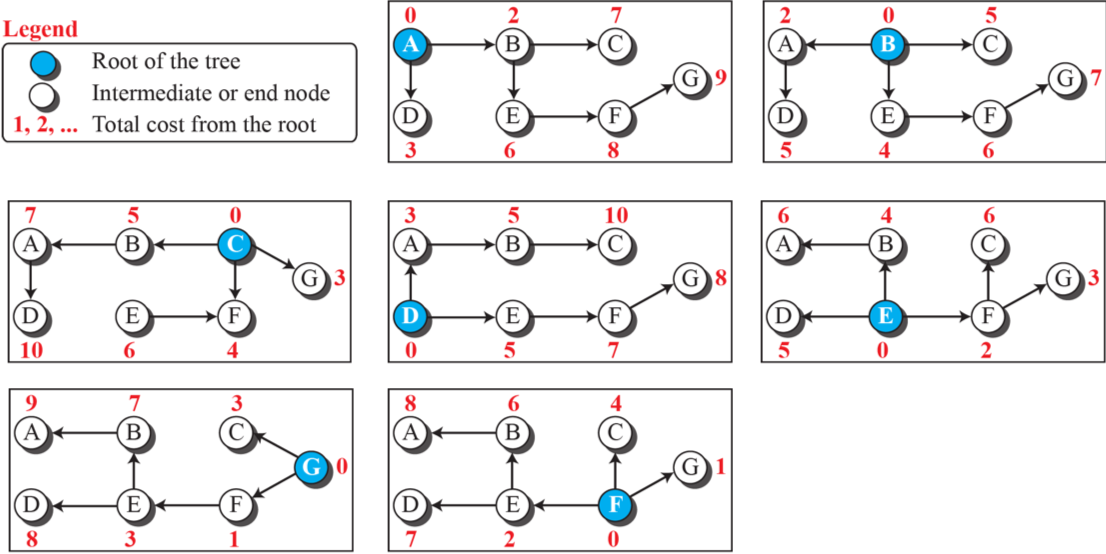
라우팅 알고리즘
여러 라우팅 알고리즘 방법들의 차이점은 최소비용과 각 노드에서 최소 비용 트리를 만드는 방법을 표현하는 방식의 차이입니다.
그럼 거리벡터 라우팅, 링크상태 라우팅, 경로 벡터 라우팅 알고리즘에 대해 설명드리겠습니다.
1. 거리-벡터 라우팅(DV, distance-vector)
자신이 알고 있는 전체 라우터의 정보를 이웃 라우터에 전달
- 각 노드의 인접한 노드들의 정보를 이용하여 최소 비용 트리를 구한다.
- 불완전한 트리(최적의 비용 정보가 아니라, 근원지 이웃한 노드들의 정보만 가지고 작성한 최소 비용 트리)는 계속 완전한 트리가 되기위해 수정한다.
- 각 라우터들은 자신이 가지고 있는 인터넷 정보가 불완전해도 정보들을 주위 라우터들에게 끊임없이 알려준다.
불완전한 트리를 완전한 트리로 바꾸기 위해 내부적으로 사용하는 개념들이 있습니다.
벨만-포드 방정식
거리 벡터 라우팅의 내부적으로 완전한 트리를 만들기 위해 사용되는 알고리즘입니다.
간단하게 모든 경로 거리를 구해 최소값을 구하는 간단한 알고리즘입니다.
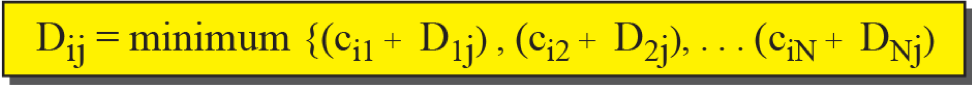
거리 벡터
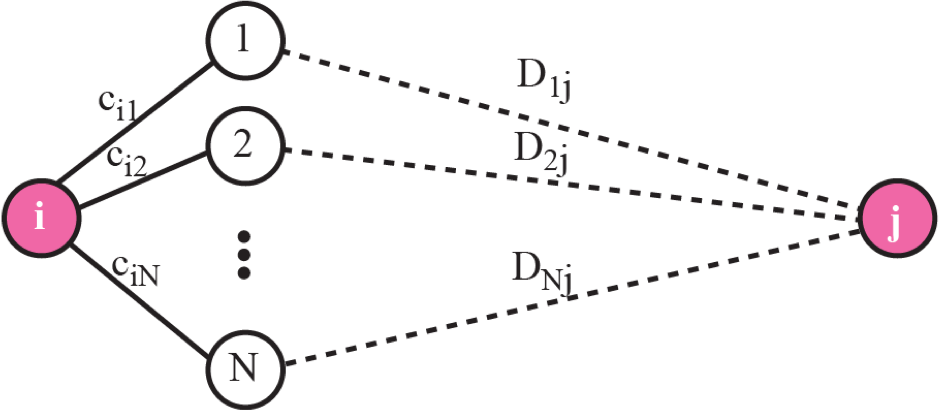
최소 비용 트리는 트리의 루트에서부터 모든 목적지까지의 최소 비용 경로 정보를 가지고 있는데, 이 정보들을 일차원 배열로 저장한 것을 거리 벡터라고 합니다.
각 라우터는 주변 노드와의 비용정보를 활용하여 거리 벡터를 생성
- 처음 값을 모를 때는 무한대로 표시
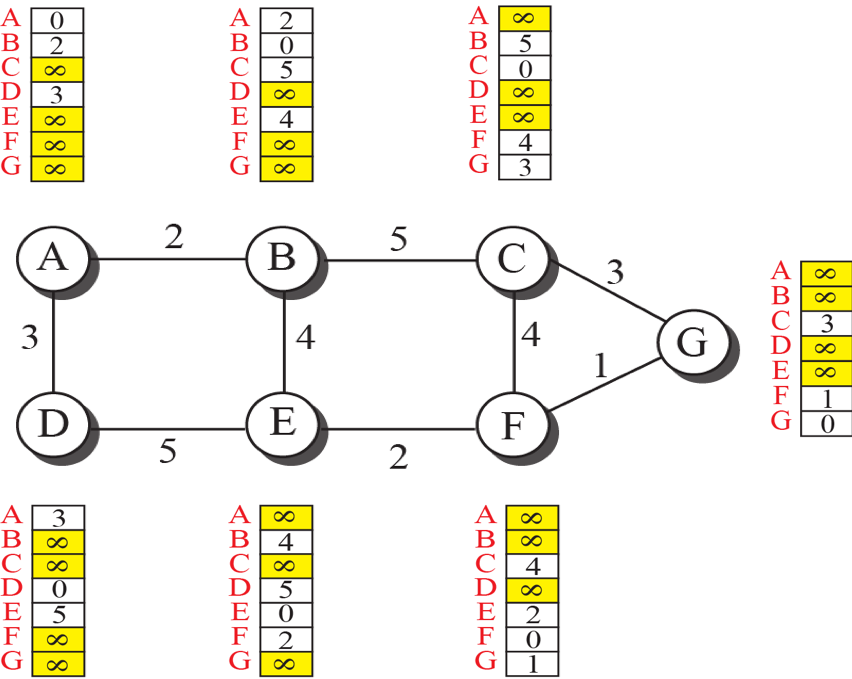
거리 벡터 갱신
불완전한 트리를 완전한 트리로 바꾸기 위해 거리 벡터를 계속 최저 비용으로 갱신해야 합니다.
- 모든 노드가 벡터를 만든 후 인접한 노드와 벡터 정보를 교환
- 이웃으로부터 벡터 정보를 수신한 노드는 벨만-포드 방정식을 이용하여 자신의 거리 벡터를 갱신 (최저 비용정보를 갱신)
- 백터가 갱신되면 자신의 모든 이웃에게 전달
- 전역적인 최소 비용을 찾을 수 있음
거리 벡터 라우팅의 단점
- 비용 감소와 같은 소식은 빨리 퍼지나 비용 증가와 같은 안좋은 소식은 갱신이 느림
- Route poisoning : 특정 네트워크가 사용불가일 경우 인접 라우터에게 무한대와 같은 높은 비용 값을 전달하여 다운 상태를 알림
- 링크가 고장 난 경우에 다른 모든 라우터가 이를 인식해야 하는데, 거리 벡터 라우팅에서는 시간이 많이 소요
- 무한대로의 카운트(count to infinity)라 불리는 문제 발생
무한대로의 카운트
이 문제가 발생하는 여러 예시가 있다.
- 두 노드의 불안정성(two-node instability)
- 해결 방안 1 : 수평 분할(split horizon)
- 해결 방안 2 : 포이즌 리버스(poison reverse)
- 세 노드의 불안정성
- 세 노드 간에 불안정성이 발생하면 이 문제의 해결이 보장되지 않는다.
거리벡터 라우팅 알고리즘의 대표적인 프로토콜은 RIP 입니다.
- RIP 패킷 구조

- Command
- 1이면 요구, 0이면 응답
- 초기에 요구를 받으면 즉시 응답해야 함
- IP Address
- 네트워크 지칭 (0으로 끝남)
- Metric
- 목적지 네트워크까지 홉 수
2. 링크-상태 라우팅
이웃하는 라우터 정보를 전체 라우터에게 전달
인터넷에서 네트워크를 나타내는 링크의 특성을 결정하기 위해 링크 상태를 사용한다. 만약 도메인 내의 각 라우터가 도메인의 전체 상태를 알고 있다면 최소 비용의 라우팅 테이블을 만들 수 있다.
- 각 노드에 의해 링크 상태 패킷(LSP: Link State Packet) 생성
- 도메인의 토폴로지에 변화가 있는 경우
- 주기적으로 생성 (1 – 2 시간)
- 다른 모든 라우터에 LSP 전송: 플러딩(flooding)
- 한 노드가 인접 노드로 부터 LSP를 받았을 때 이 LSP가 새것이면 이를 갱신하고 송신 노드를 제외한 각 인터페이스의 외부로 전송
- 각 노드에서 최소 비용 트리 생성(Dijkstra 알고리즘 적용)
- 최소 비용 트리를 기반으로 한 테이블 계산
링크-상태 데이터베이스
링크-상태 라우팅을 사용하여 최소 비용 트리를 작성하기 위해 각 노드는 각 링크의 상태를 알아야 하기 때문에 네트워크의 완전한 맵(map)이 필요하다. 그런 모든 인터넷에 대해 딱 하나만 존재하는 링크의 상태 집합을 링크-상태 데이터베이스(LSDB, Link-State DataBase)라 부른다.
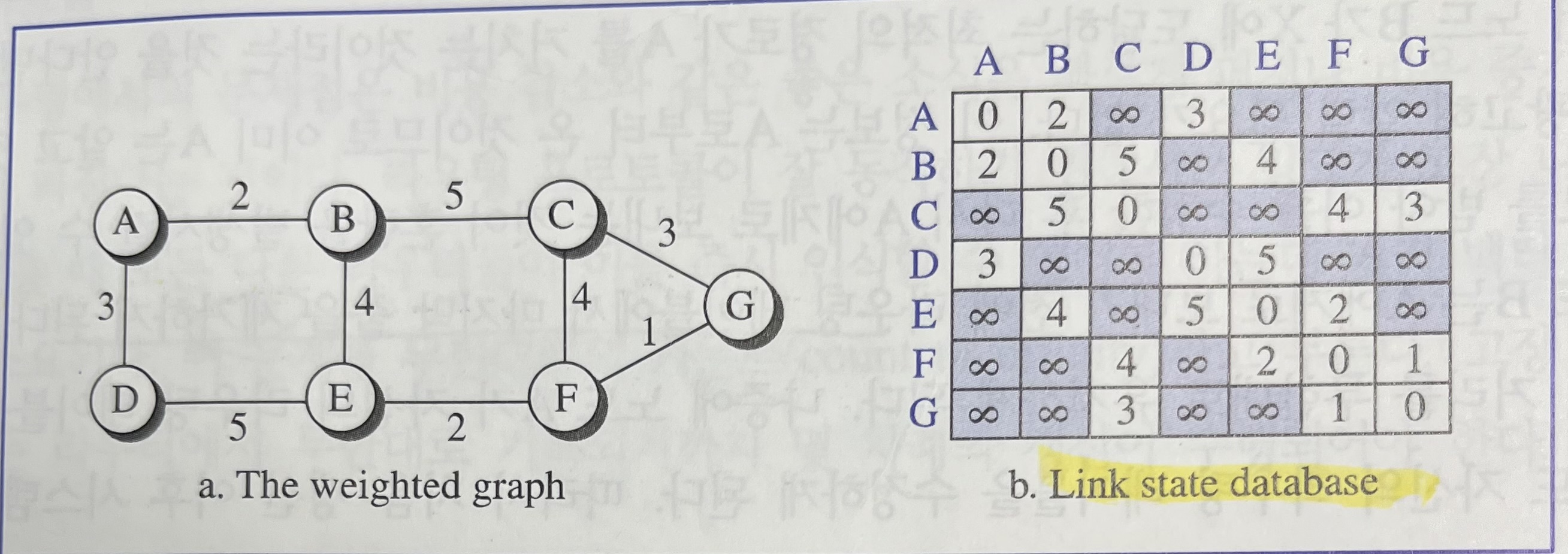
다이크스트라(Dijkstra) 알고리즘(= 알고리즘 시간에 배운 다익스트라)
각 노드에서 최소 비용 트리를 생성하기 위한 알고리즘입니다.
- 자기 자신을 루트로 선택하고 각 노드의 전체 비용을 계산
- 트리에 속하지 않은 모든 노드 중 루트와 가장 근접한 하나의 노드를 선택, 모든 트리 비용 계산
- 트리에 모든 노드가 추가될 때 까지 2단계 반복
링크 상태 알고리즘의 대표적인 프로토콜은 OSPF입니다.
OSPF 토폴로지
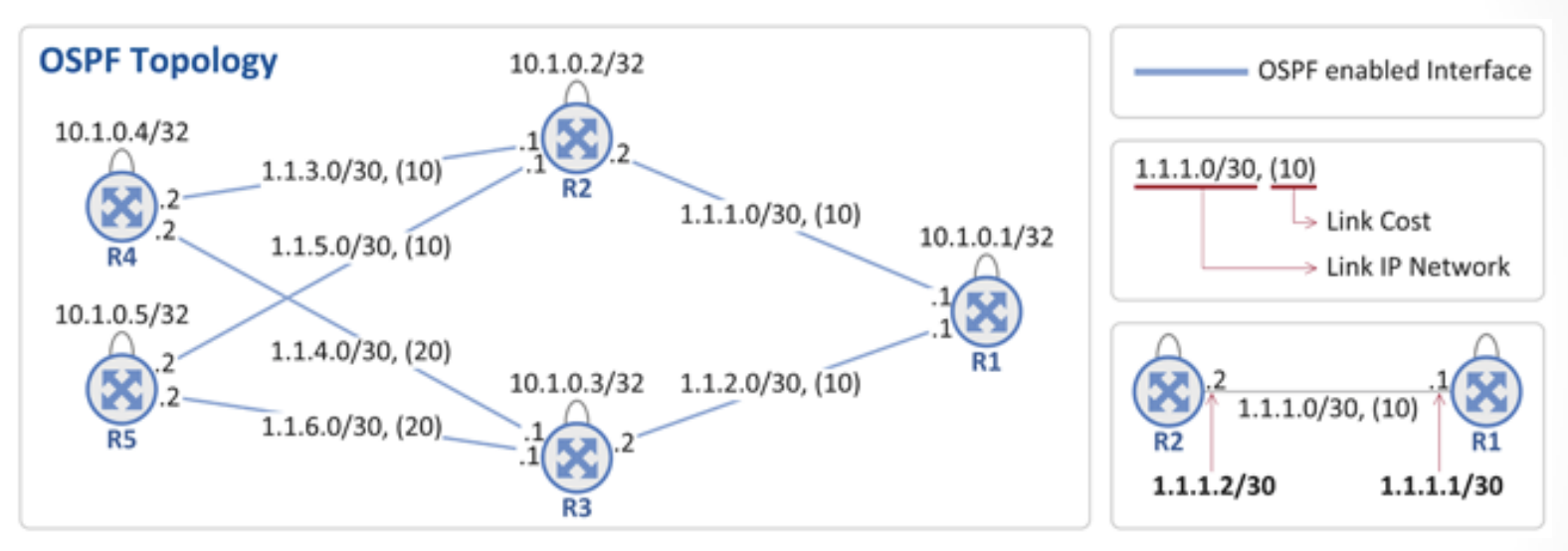
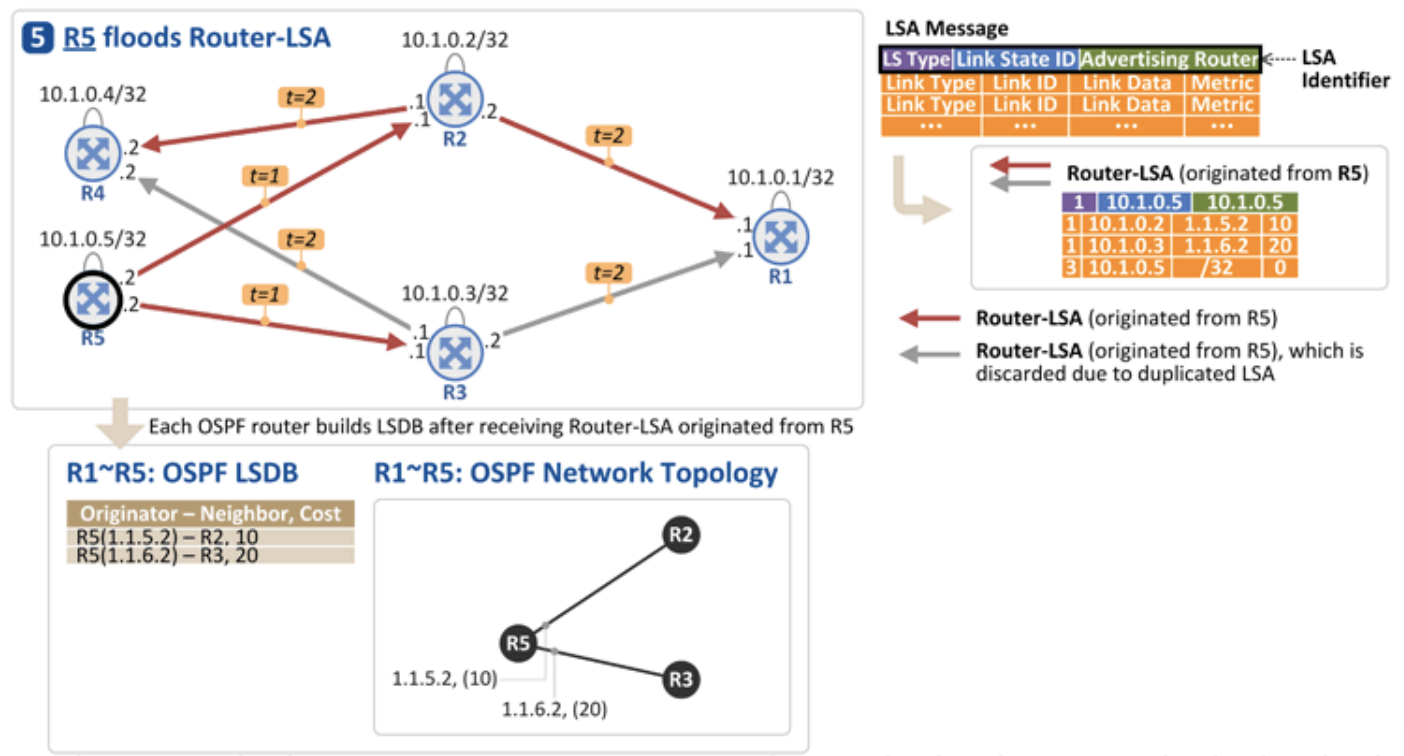
- 5개의 OSPF 라우터(R1~R5) 존재
- 라우터간 연결 링크에 대한 IP 주소(예 - R1과 R2 사이 1.1.1.0/30)와 OSPF Cost(예 - R1과 R2 사이 (10)) 및 각 라우터의 Loopback 주소(*예 - R1의 10.1.0.1) 표시
- 파란색 줄(링크)가 OSPF가 enable임을 표시
각 라우터가 링크 정보를 전파하는 방식과 순서
- R1

- ‘R1은 R2, R3에 연결되어 있다’는 링크 정보를 다른 라우터에게 전달하려면,
- R1에 연결된 모든 라우터(R2, R3)에 정보 전달
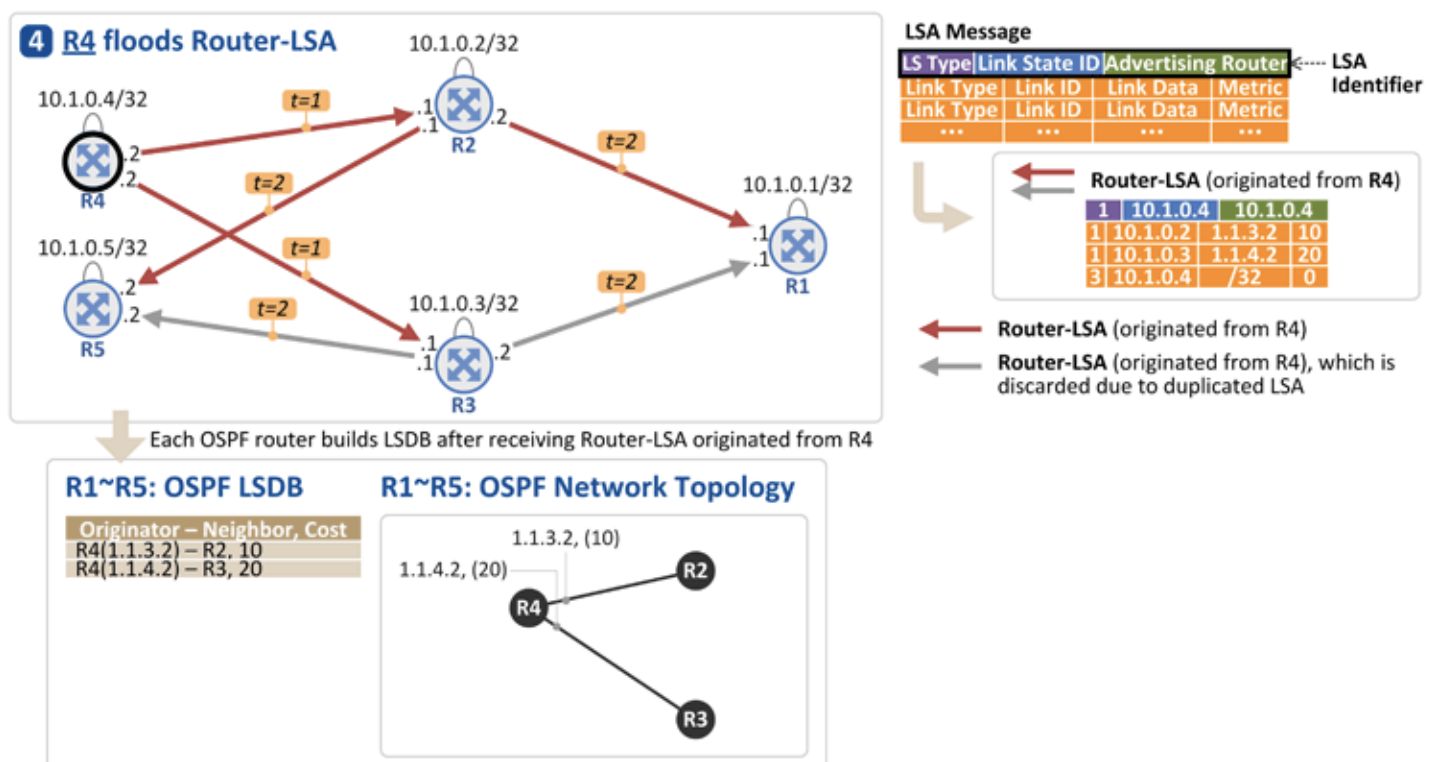
- R2는 정보를 받은 R1을 제외하고 R4, R5에 전달
- R3도 R1을 제외하고 연결된 R4, R5에 전달
- R4, R5는 동일한 Router-LSA를 2개씩 수신
- LSA 식별자에 해당하는 LS Type, Link State ID, Advertising Router가 동일한 경우 나중에 수신한 LSA를 폐기
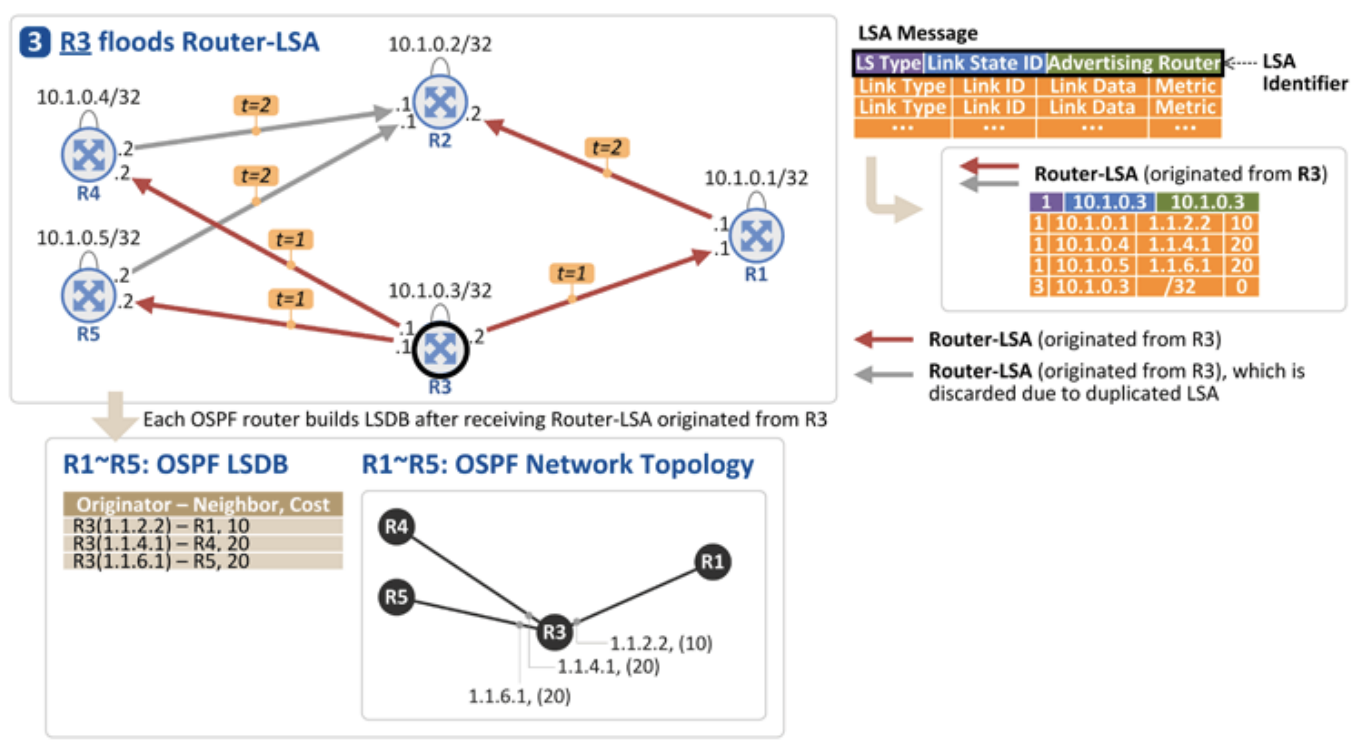
- 여기에서는 R2로부터 온 정보가 더 먼저 도착했기 때문에(Cost가 10으로 Cost가 20인 R3보다 빠름) R3로부터 받은 정보는 폐기함
- R2

- 자신의 링크 정보를 다른 OSPF 라우터로 전파
- 이를 수신한 R1, R4, R5는 Router-LSA가 수신된 링크를 제외한 나머지 링크로 플러딩
- R3은 동일한 Router-LSA를 3개 수신
- 가장 먼저 수신한 것(R1으로부터)을 제외한 나머지 폐기
- R3
- R4
- R5
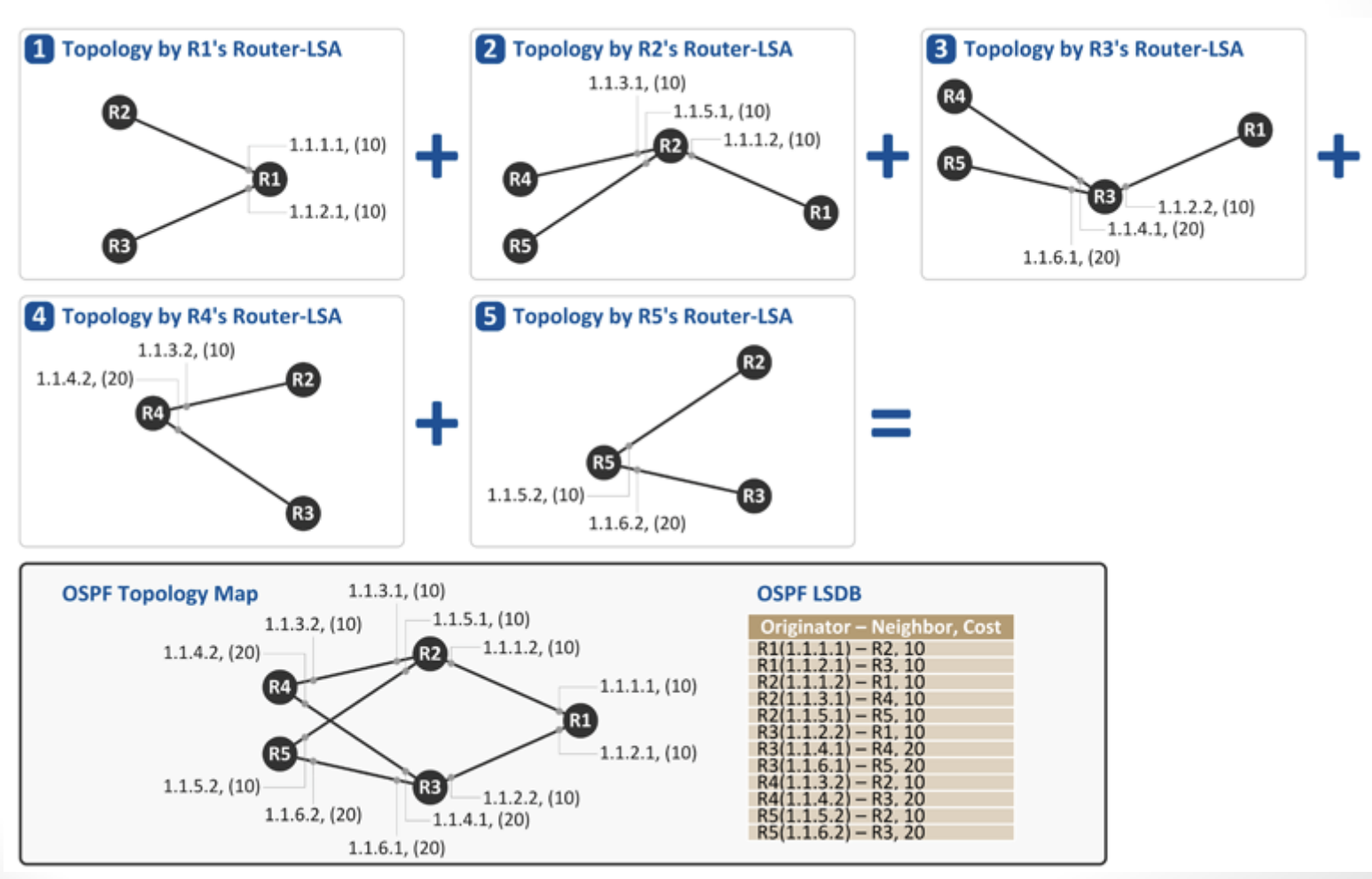
모든 정보를 모아서 전체 그림을 그림
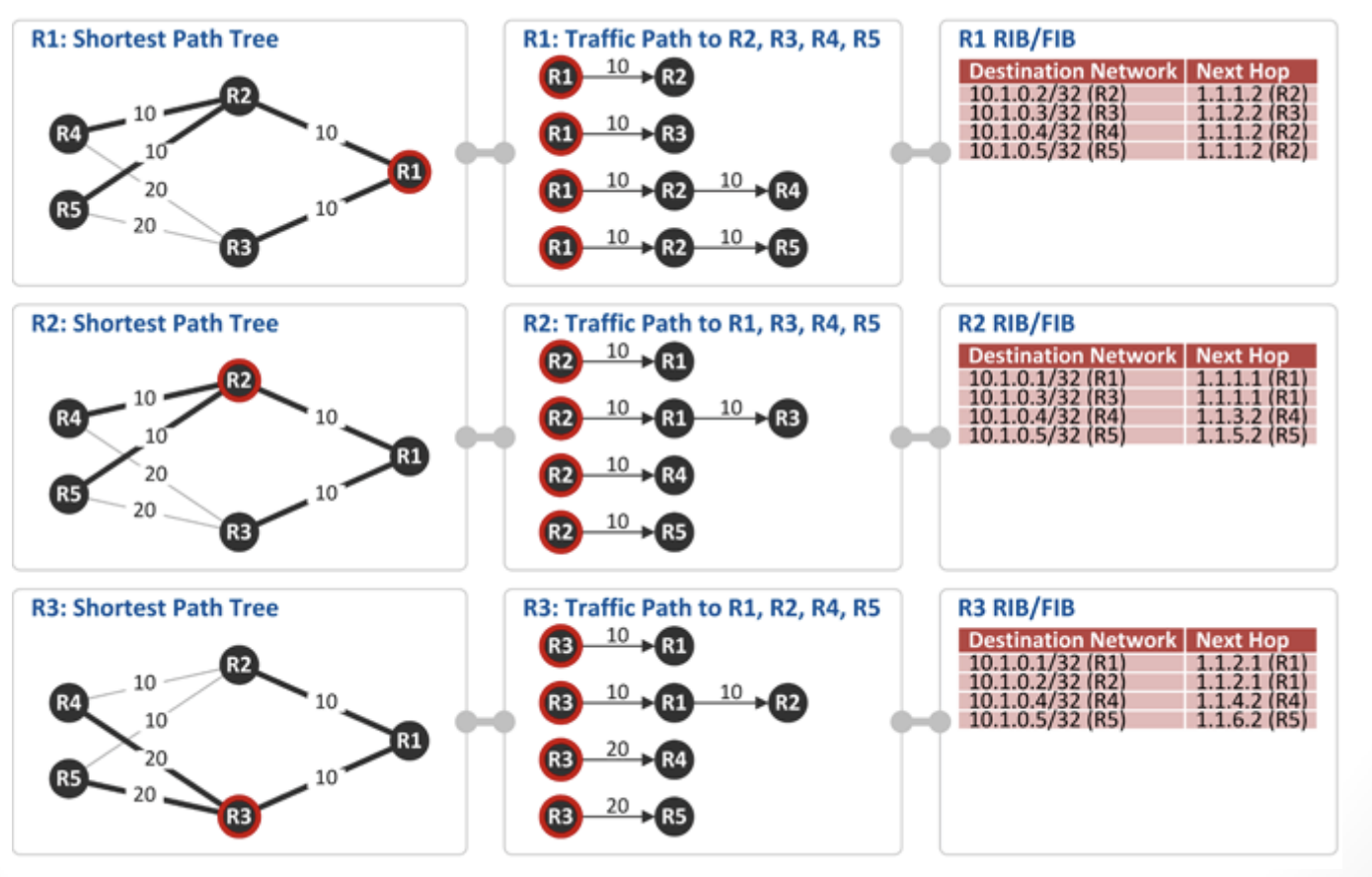
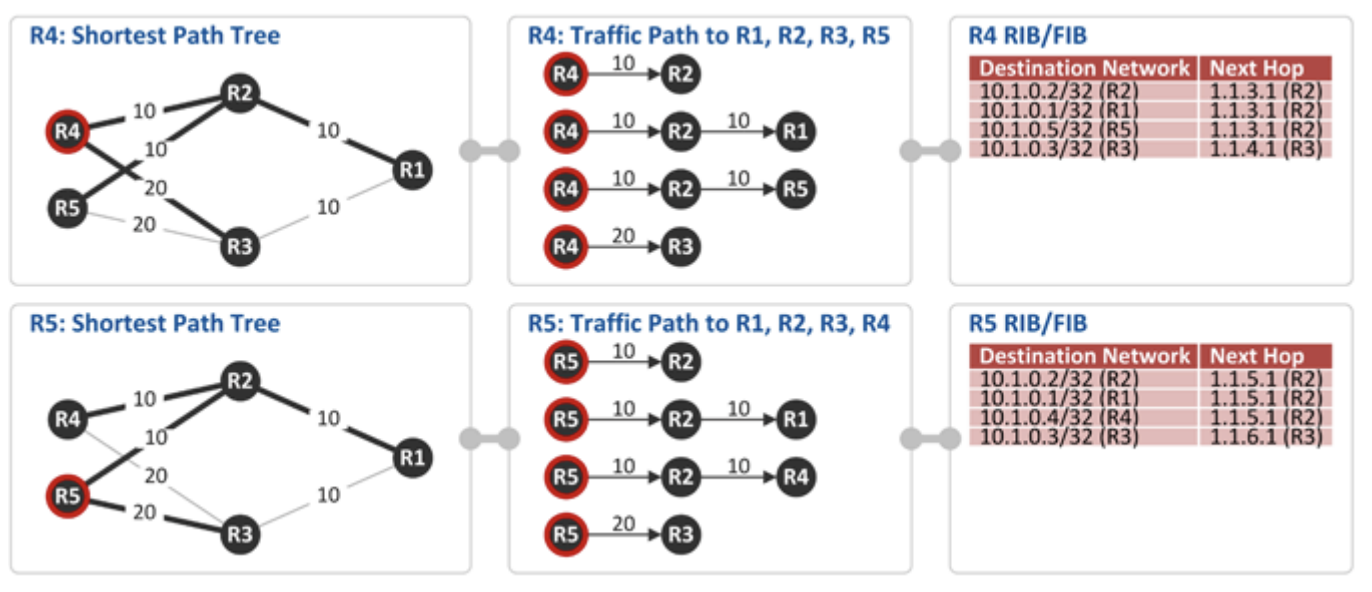
최단 경로(=cost가 가장 적은) 트리 구성
3. 경로-벡터(PV, Path-Vector) 라우팅
링크-상태나 거리-벡터와는 다르게 최소 비용을 목표로 하는 것보다 발신자가 라우터에게 특정한 규칙을 적용시킬 수 있다.
배경
- 거리 벡터와 링크 상태 라우팅은 도메인 내부 라우팅에만 사용됨.
- 확장성으로 인해 도메인 간 라우팅에는 대부분 부적합
- 거리 벡터 라우팅은 동작하는 도메인에 수 홉 이상이 존재하게 되면 불안정해질 수 있다.
- 링크 상태 라우팅은 라우팅 테이블을 계산하기 위해 아주 많은 양의 자원을 필요로 한다. 이는 또한 플러딩으로 인해 많은 트래픽을 유발할 수도 있다.
- 거리와 링크 상태 뿐 아니라 특정 서비스를 위한 정책적인 제어가 필요함.
따라서 제3의 라우팅 프로토콜이 요구되었습니다.
⏬
경로 벡터 라우팅(path vector routing)
스패닝 트리를 활용하여 경로를 결정
스패닝 트리
- 최소 비용 트리가 아니다.
- 스패닝 트리 고유 규칙을 적용 해 발신지로부터 작성되는 트리
- 벨만-포드 방정식과 비슷하나 최소 비용이 아닌 고유 규칙을 이용한다.
Path(x, y) = best {Path(x, y), [(x + Path(v, y)]} for all v’s in the internet
거리벡터, 링크상태 비교 표
| 장점 | – 라우팅 테이블 크기 작아 메모리 절약 – 라우팅 구성 간단 |
– 거리와 대역폭에 따라 경로 계산 – 라우팅 정보 변화 시 변경 정보 전달 |
| 단점 | – 주기적 라우팅정보 갱신 트래픽 낭비 – 라우팅 정보 변화 시 전달 느림 |
– 모든 라우팅 정보 관리로 메모리 소모 – SPF 계산 등 CPU 로드 소요 |
| 적합 | – 소규모 네트워크 | – 대규모 네트워크 |
| 알고리즘 | – 벨만-포드 알고리즘 | – 다익스트라알고리즘 |
| 네트워크 정보 |
– 이웃한 라우터 시각 네트워크 인식 | – 네트워크 전체 인식 |
| 경로 계산 방식 |
– 홉 카운트로 계산 | – 홉, 지연, 대역폭 등 – 다양한 변수 고려 |
| 라우팅 정보 갱신 |
– 주기적으로 라우팅 테이블 갱신 | – 이벤트 기반 라우팅 테이블 갱신 |
| 라우팅 정보 교환 |
– 인접 라우터와 거리 정보를 교환 | – 인접 라우터와 링크 상태 정보를 교환 |
| 라우팅 프로토콜 |
– RIP, IGRP | – OSPF, IS-IS |
RIP OSPF 비교
| 항목 | RIP | OSPF |
| 경로 설정 |
– DistanceVector – Hop count 네트워크 당 ‘1’ |
– Link-State – 라우터 계층 – Short-path계산 |
| 메시지 교환 |
– RIP Request 주기적 요청 |
– LSA 전송 망변화 시 수행 |
| 장점 | – 구성 간단 | – 확장성/가용성 |
| 단점 | – Hop count제한 | – 구성 복잡 |
| 활용 | – 소규모 망 | – 중/대형 망 |
'computer science👩💻' 카테고리의 다른 글
| [DB] 데이터베이스 시스템 1장 (1) | 2022.11.23 |
|---|---|
| [Network] 웹 접속 방식 (3) | 2022.10.03 |
| [Network] TCP/IP 흐름제어, 혼잡제어 (6) | 2022.09.19 |
| [Network] 매체 접근 제어 방식 (11) | 2022.08.14 |
| github colab 연동 및 업로드 방법 (0) | 2022.03.02 |
- Total
- Today
- Yesterday
- 문자열뒤집기
- 1이될때까지
- boj1260
- 토익 #900점 #토익독학길잡이 #토익독학 #토익공부법
- 매체접근제어
- 느는중
- aimd
- tahoe
- 거리벡터
- ssafy #싸피 #8기 #ssafy전공자
- Colab
- 데이터베이스시스템
- 백준1260
- 14888
- 백준 #1158 #java
- slowstart
- 이코테
- 정보컴퓨터
- reno
- 파이썬
- 라우팅알고리즘
- tcp/ip흐름제어
- 그리디
- 모험가길드
- 링크상태
- 큰수의법칙
- CSMA
- 네트워크
- 연산자끼워넣기
- DFS와BFS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |